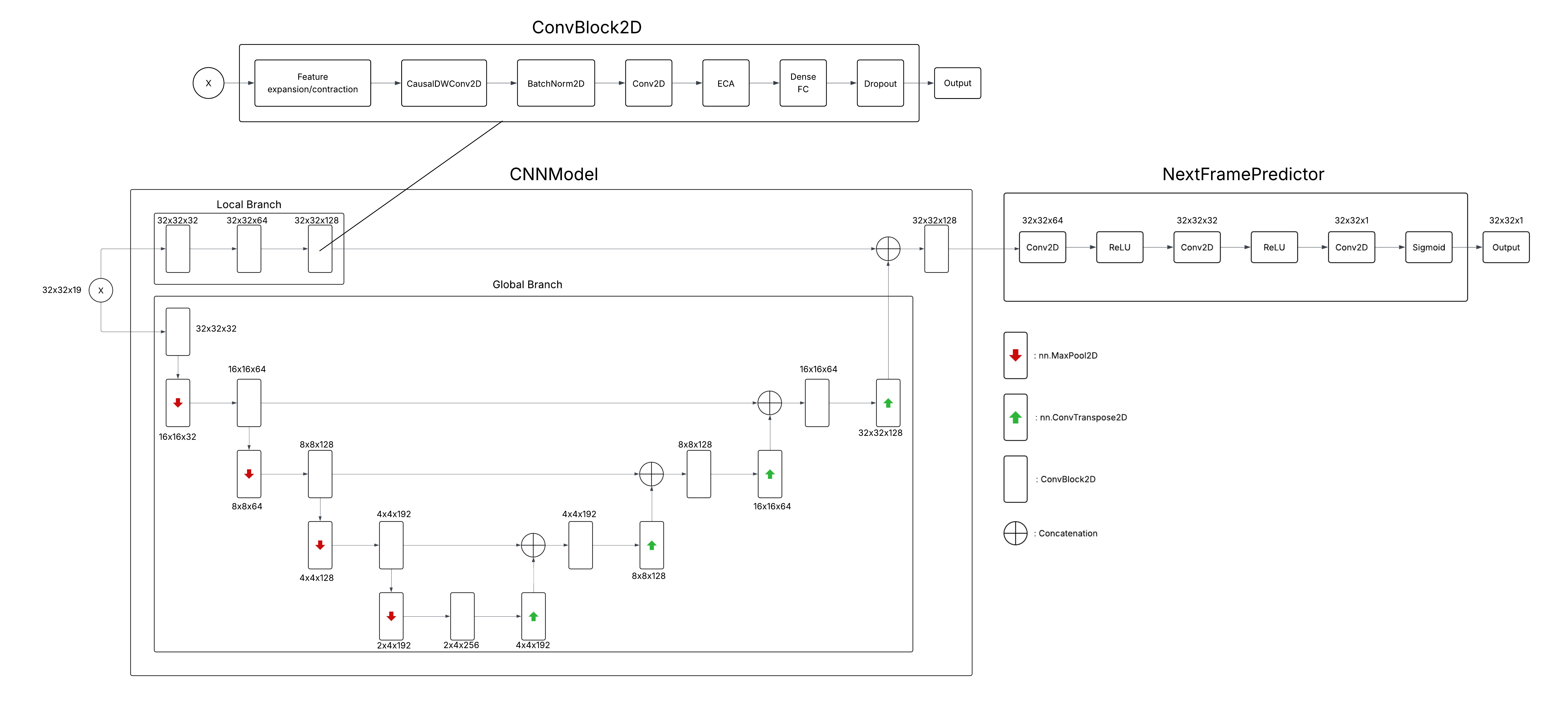
Model Architecture
To provide actionable insights to emergency responders and wildfire management services, we needed a robust model architecture to produce clear and precise wildfire spread predictions. Taking inspiration from other models, we first developed a spatiotemporal architecture that processed the 19 environmental covariates from the enriched NDWS dataset, leveraging CNNs for spatial feature extraction, and Transformers and ConvLSTMs to capture temporal dynamics. But due to insufficient sequential data in the enriched NDWS dataset, the temporal components of the architecture were dropped after primary experimentation.
The final model employs two components, the CNNModel that extracts spatial features and the NextFramePredictor that predicts the next day's wildfire spread map from the extracted spatial features. Important: The original 64×64 pixel data is center-cropped to 32×32 pixels before being input into the model to match the training configuration.
How CinderSight Works
Detailed architecture overview
Spatial Feature Extraction (CNNModel)
Input: 32×32×171 feature maps (19 original features × 9 spatial positions from surrounding pixels)
Composed of two parallel feature extraction paths:
- Preserves spatial resolution for detailed feature extraction.
- Applies convolutional blocks (Conv2DBlock) sequentially, gradually increasing channels.
- Captures broader contextual information through downsampling (MaxPool2D) and upsampling (ConvTranspose2d).
- Uses skip connections to merge downsampled and upsampled features at multiple scales.
- Ends with a bottleneck, then progressively upscales the data back to the original resolution.
Local Branch:
Global Branch:
Both branches are concatenated into a unified feature map that goes through a final convolutional block to yield rich spatial representations that capture both local and broad contextual features.
Spatial Context: The 171 input channels are created by the add_surrounding_position function, which expands each pixel's 19 features to include information from its 8 neighboring pixels (center + 8 neighbors = 9 positions × 19 features = 171 channels). This provides crucial spatial context for wildfire spread prediction.
Conv2DBlock
Key component within CNNModel:
- Uses depthwise convolutions with causal padding (CausalDWConv2D), capturing spatial patterns.
- Implements attention mechanisms (ECA) to dynamically weigh channel importance.
- Applies normalisation, spatial attention, dropout, and non-linear activations (SILU).
Conv2DBlock:
Next-Day Prediction (NextFramePredictor)
Input: Feature maps from CNNModel (32×32×128)
Receives feature maps from CNNModel:
- Uses 3-layer CNN (128 → 64 → 32 → 1) with ReLU activations, concluding with a Sigmoid activation.
- Predicts the probability of wildfire presence at each spatial location with the output shape: height × width × 1
Conv2DBlock:
Our best model (v3) achieved an F1 score of 0.425, IoU of 0.270, precision of 0.312, recall of 0.669, and an inference speed of 51.0 ms.
Note: Predictions are upscaled back to 64×64 for visualization and metrics calculation to ensure proper alignment with the original ground truth data.
Custom Loss Function
Addressing class imbalance with Weighted Binary Cross-Entropy (WBCE) and Dice Loss
Challenge: Class Imbalance
• Fire pixels: Only 1.34% of the dataset (severely underrepresented)
• No-fire pixels: 97.81% of the dataset (majority class)
• Problem: Standard BCE loss would bias the model toward predicting "no-fire"
Solution: WBCE + Dice Loss
• Weighted Binary Cross-Entropy (WBCE): Assigns higher weights to fire class
• Fire class weight (w₁): 10 (10x higher importance)
• No-fire class weight (w₀): 1 (baseline importance)
• Dice Loss: Improves segmentation accuracy and boundary precision
Mathematical Formulation
WBCE Loss:
WBCE = -1/N × Σ(wᵢ × [yᵢ × log(ŷᵢ) + (1-yᵢ) × log(1-ŷᵢ)])
Weight Assignment:
wᵢ = {w₁ = 10 if yᵢ = 1 (fire), w₀ = 1 if yᵢ = 0 (no-fire)}
Combined Loss:
Total Loss = WBCE + 2 × Dice Loss
• Factor of 2: Emphasizes Dice Loss contribution for precise boundaries
• Masking: Excludes invalid pixels (marked as -1) from loss computation
• Result: Balanced training that prioritizes fire detection while maintaining accuracy
Model Architecture
Diagram of our final prediction model architecture